코드 재사용을 최대화하는 Redux 스토어 정규화
Redux의 가장 큰 장점 중 하나는 애플리케이션 상태가 하나의 진리의 원천(single source of truth)을 포함한다는 것이다. 그 상태 데이터는 정규화된 구조로 저장된다. 따라서 최소한의 노력으로 비즈니스 로직을 공유하거나 확장할 수 있다. 단점은 Redux가 비일반적인 양의 보일러플레이트를 필요로 한다는 것이다. 그러나 이런 유연성이, 내 의견으로는, 당신으로 하여금 이 보일러플레이트를 구매하게 하는 주요 이점중에 하나다.
MobX와 같은 객체 지향 솔루션은 보일러플레이트를 줄이지만, 테스트가능하고, 응집되어 있으되, 지나치게 결합하지 않은 - 다른 말로는 객체 지향적인 - 애플리케이션 상태를 구성하는 당신 자신만의 방법을 요구한다. 이 선택지가 “더 좋은” 방법인 것은 아니다. 모든 프로젝트가 요구사항에 기초하여 절충해야만 하는 것이다. 강조하기 위해 추가하건대, 나는 MobX를 직장에서 프로페셔널하게 사용하고, 아주 좋아한다. OOP의 오버헤드가 Redux가 요구하는 것 보다 적을 수도 있고, 혹은 Knockout 같이 오래된 OOP 기반 프레임워크로 작성된 레거시 코드는 정규화된 Redux Store 보다는 MobX로 변환하는 것이 더 쉽다.
이 포스트는 Redux의 강점을 강조하는 유스케이스 하나를 보여준다. 일부러 찾으려고 한 것은 아니지만, 내 사이드 프로젝트 중 하나를 시작한 후로, Redux에서 특히 잘 작동하는 피처를 추가하고 있었다. 최근 내가 Redux에 제기된 비판을 본 것이 내가 이 글을 쓰는 동기가 되었다.
이 포스트는 Redux와 스토어를 정규화 하는 것에 익숙한 사람을 독자로 가정했다. 내 이전 포스트에서 이 문제에 대해 자세히 논의한 적이 있다. 아래의 샘플 코드는 메모이징 Redux 셀렉터 작성 툴인 reselect를 자유롭게 사용하고 있다.
유스케이스
이전과 마찬가지로 코드 샘플은 내 북-트랙킹 웹사이트에서 가져온 것이다. 나는 이것을 내 자신만을 위한 라이브러리로 사용하고 또한 여기에다 새로운 것을 시도한다. 나는 이것을 작성함으로써 React를 배웠고, 결과적으로 큰 성공과 함께 팀을 바꿨기 때문에 시간을 잘 보냈다고 할 수 있다 :)
특히, 사용자는 계층적인 주제의 컬렉션을 저장할 수 있다: 예를 들면, 미국 혁명은 미국 역사 아래 두고, 이는 다시 역사 아래 놓을 수 있다. 계층 구조는 Mongo에서 materialized paths로 저장된다.
나는 코드에서 주제들이 어떻게 저장되는지와, 정규화된 상태가 약간 미묘하게 다른 방식으로 재사용될 수 있는지 간략하게 설명할 것이다.
다음과 같은 내용을 강조한다: MobX에서는 이를 많은 추가 작업없이 달성하기가 힘들다는 것이다. 요점은 내가 보여주고 싶은 것이 Redux가 어떻게 잘 동작하는지 보여주는 것 뿐 아니라, 내 의견으로는, 더 나은 대안이 될 수 있다는 것이라는 것이다.
주제 저장하기
여기 내 주요 애플리케이션 레벨의 저장소에 대한 단순화 버전이 있다:
서브젝트가 되돌아왔을 떄, 그들은 해쉬에 평평하게 들어간다. 그러고나서, 이 해쉬를 다시 유용한 콜렉션으로 모양을 바꿔주는 메서드들이 익스포트되고, 애플리케이션 내 다른 부분들에 의해 필요에 따라 사용된다.
예를 들어 도서 목록을 표시하는 애플리케이션에서 대상을 필터에 의해 검색하고 선택하거나, 도서 목록에 도서를 추가하는 부분은 다음과 같다.
동일한 subjectHash가 애플리케이션 상태에서 다른 부분에 의해 추출되고, 그 다음에는 stackAndGetTopLevelSubjects 메서드로 모양을 바꾼다. 그리고 그 결과를 리듀서의 나머지 상태 부분과 결합한다.
코드 확장하기
더 흥미로운 부분은, 서브젝트의 상세 정보를 수정하는 애플리케이션의 또다른 파트다. 서브젝트들이 모두 계층적으로 목록에 표시되고, 사용자는 그들을 새로운 부모에게 드래그앤 드랍한다. 하지만, 서브젝트는 새로운 유효한 부모들에게 호버링 중일 때, 부모는 서브젝트가 하위 자식들로 들어오는 것이 보류 중임을 보여주고, 사용자는 드랍을 완료하기 전에 시각적인 유효성 검사를 볼 수 있게 된다. (스타일링은 언제나처럼 진행 중인 작업이다)
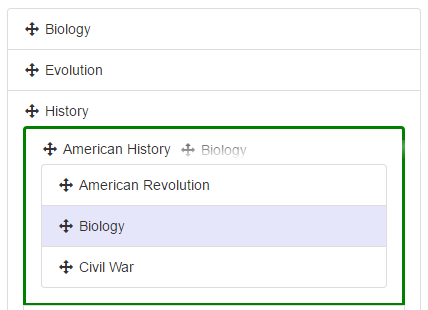
문제의 리듀서는 드랍이 보류 중임을 나타내는 액션을 받아들이고, 새로운 서브젝트 해쉬를 받아들이기 위해 새로운 임시적인 서브젝트를 새로운 부모 아래쪽에 보여주도록 살짝 조정한다.
기본적으로 5줄 미만의 if(currentDropCandidateId){가 서브젝트 해쉬의 shallow copy를 생성하고, 드래깅 중인 서브젝트의 복사본을 드랍 타겟의 자식의 경로를 갖도록 생성하고 추가한다. 그게 전부다.
그리고 currentDropCandidateId가 없으면 임포트된 subjectsSelectoris를 호출한다. 맞다, 이 셀렉터는 그저 stackAndGetTopLevelSubjectsinternally를 호출할 뿐이고, 그래서 같은 메서드를 호출하는 것으로 if 아래에 else 3행을 절약하게 해준다. 하지만 subjectsSelectoris는 개별적으로 메모이즈드되고, 어떤 재계산도 일으키지 않는다.
따라가다보면, 드래그가 있을 때마다 드랍 타겟이 명백히 변경되지 않았더라도 각 서브젝트가 stackAndGetTopLevelSubjects에서 재계산되지만, 이는 ES6 Map과 간단한 캐싱에 의해 아주 쉽게 향상시킬 수 있다. 사실 나는 이런 성능 최적화들이 실제에 어떤 영향을 미칠 수 있을 지는 의심스럽다; 그러나 비합리성과 비효율성이 나를 괴롭히고 있기 떄문에, 그리고 이러한 도구를 가지고 작업하는 것이 좋은 경험이 될 것이기 때문에, 그렇게 한다.
정규화의 이점
MobX로도 이렇게 할 수 있었냐고? 물론이다. 그리고 그렇게 어렵지도 않을 것이다. 아마도 주요 서브젝트들이 옵저버블 어레이—주요 서브젝트들과 현재 drop id를 읽는 계산이 거기서 이루어질 것이다. 만약 dropId가 없으면 주요 서브젝트 어레이가 리턴될 것이다. dropId가 있는 경우에는 대상 서브젝트가 복제되고 대체되야 할 것이다. 즉, 드래그된 서브젝트의 복사본이 대상의 하위 자식으로 추가될 것이다—MobX의 invariants를 위반하는 일 없이: observables는 계산된 속성 정의 안에서는 절대 수정될 수 없다. 그리고, 물론 대상 서브젝트는 얼마나 깊은 계층 구조를 가졌냐에 상관없이 발견되야 할 것이다. 그러므로, 그것을 탐색하기위한 종류의 computed lookup map이 주요 서브젝트 어레이에 정의되어야 한다. 아마도 가능하겠지만, Redux의 솔루션이 더 직관적이라고 생각한다.
아니면 내가 모르는 더 간단한 방법이 있을 수도 있다. 그렇더라도, 이 데모가 보여주듯이, Redux는 근본적으로 유연하고 단순한 패러다임으로 당신을 강제한다.
결론
은탄환은 없다. 두 접근법 모두 장단점이 있고 그것을 이해해야 한다. Redux의 normalized data를 저장하는 접근법은 고유한 유연성을 제공하지만, 많은 양의 보일러 플레이트가 필요하고, 비경험자에게는 코드가 직관적이지 않다.
유연성에 대한 수요가 크지 않은 경우에는 MobX를 사용하는 것이 좋다. 계단식 반응을 이끄는 MobX의 능력은, “스프레드시트”와 같은 사례에 일반적으로 적합하다.
이 글을 쓰는 주된 동기는 Redux에 대한 비판에 대해 싸우려는 것이다. 맞다. 더 많은 코드가 필요하지만, 고유의 이점도 제공한다.