원문보기
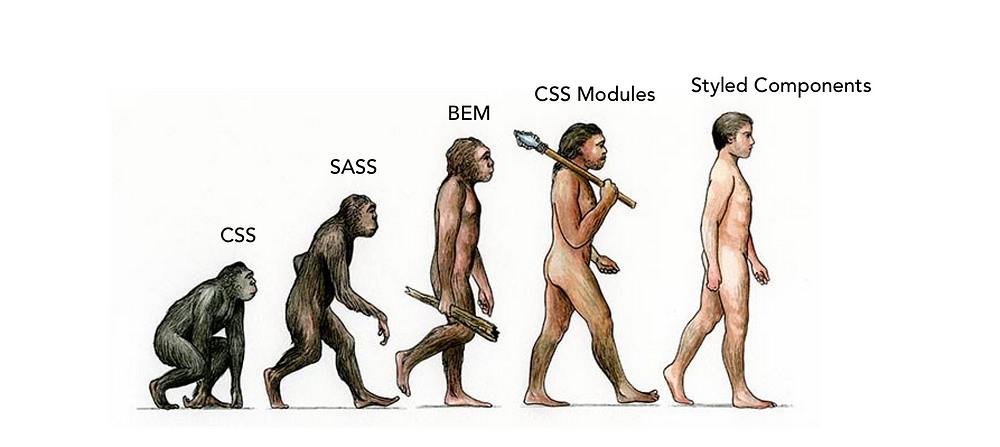
CSS의 진화: CSS, SASS, BEM, CSS Modules로부터 Styled Components로
초기 인터넷 시절부터 우리는 항상 웹사이트를 스타일링할 필요가 있었다. CSS는 영원히 계속되었고 지난 몇 년간 독자적인 페이스로 발전해왔다. 이 기사를 통해 여러분과 그 지난 몇 년 간을 짚어본다.
CSS는 무엇과 함께 있어야할 필요가 있는지 먼저 생각해보자. 당신들 모두 CSS를 마크업 언어로 작성된 문서의 표현을 기술하는데 사용되야 한다는 데에 동의할 것이다.
CSS가 강력해졌고 진화해졌다는 뉴스는 없지만, CSS를 어떻게든 활용할 수 있도록 추가적인 도구들이 있다는 것은 널리 알려져 있다.
미개척 서부의 CSS
90년대에 우리는 “멋진” 인터페이스를 만드는데 중점을 뒀다. 와우 팩터는 가장 중요한 것이었고, inline style이 그당시에 쓰였던 것이다. 그리고, 우리는 그저 다르게 보이게 하는 것이라면 다른 것은 신경쓰지 않았고, 결국 웹페이지는 몇몇 gifs와 marquees, 끔찍한(당시에는 인상적인) 엘레멘트를 이용해서 방문객의 주의를 끌기를 기대하는 귀여운 장난감처럼 보였었다.
그 후에 동적 사이트를 만들기 시작했을 때 각 개발자들이 css를 다루는 자신만의 방법을 가지는 일관성 없는 상태로 남겨졌다. 우리 중 몇몇은 새 코드를 도입할때 비주얼 리그레션을 일으키는 특수함과 사투를 펼쳤다. 우리는 !important에 의존해서 UI를 정확히 특정한 방식으로 보이게 하려고 했으나, 곧 깨달았다:

프로젝트의 규모, 복잡성 및 팀 구성원이 증가함에 따라 이러한 모든 관행들이 더욱 분명하고 큰 문제가 되었다. 따라서 스타일을 유지하는 데 있어서 개발자의 경험이 많고 적음을 가리지않고를 떠나 모두가 일관된 패턴을 갖추지 못한 CSS를 다루는 올바른 방법을 찾기위해 사투를 펼쳤다. 그러나 결국, 올바른지 아닌지는 상관하지 않고, 그저 제대로 보이기만 하면 되는데 신경을 쓰게 되었다.

SASS 구조대
SASS는 중첩, 변수, 믹스, 확장 및 로직을 스타일시트에 구현한 전처리 엔진 형태로 CSS를 적절한 프로그래밍 언어로 변형하여 CSS 파일을 보다 잘 구성하고 CSS 덩어리를 더 작은 파일로 분류할 수 있었다. 그 당시에는 아주 훌륭해 보였다.
본질적으로 그것은 SCSS 코드를 가지고 전처리하고 컴파일된 버전을 CSS 묶음으로 출력하는 것이다. 훌륭하지 않은가? 그러나 별로 말할 것도 없이, 시간이 흐르자 적절한 전략과 모범사례가 없다면 SASS는 더 많은 문제를 일으킨다는 것이 분명해졌다.
갑자기 우리는 이 전처리기가 후드 아래서 무엇을 하고 있는지 신경쓰지 못했고, lazily nesting에 의존하여 특수성과의 싸움을 정복했으나 컴파일된 스타일시트의 크기는 엄청나졌다.
BEM이 나타나기 전까지는….
BEM과 컴포넌트 기반의 생각
BEM이 나왔을 때는 공기 중에 재사용성과 컴포넌트에 대해 더 생각하게 만드는 신선한 공기가 맴돌았다. 그것은 의미론을 새로운 수준으로 끌어올렸고, 단순한 Block Element Modifier 컨벤션을 통해 className을 고유하게 만들었다. 다음 예제를 보자:
마크업을 약간 분석하면 즉시 Block Element Modifier가 여기서 놀고 있음을 알아차릴 수 있다.
.scenery와 .sky라는 블록을 가지고 있음을 확연히 알 수 있다. 각 블록들은 또 자체적인 블록을 가지고 있다. Sky는 foggy, daytime, dusk처럼 같은 엘레멘트에 적용될 수 있는 다른 특성들을 가진 유일한 엘레멘트다.
더 나은 분석을 할 수 있도록 pseudo 코드를 사용한 CSS를 살펴보자:
BEM이 어떻게 동작하는지 깊이 알고 싶다면, 내 동료이자 친구인 Andrei Popa가 작성한 이 기사를 추천한다.
BEM은 컴포넌트가 고유한 #reusabilityFtw임을 보장한다는 의미에서 유용하다. 이런 종류의 생각은 패턴으로 나타났고 예전 스타일 시트를 이 새로운 컨벤션으로 이전하기 시작하면서 더 명백해졌다.
그러나, 또 다른 문제들이 발생했다:
- 클래스 이름으로 셀렉트하는 일이 끔찍한 일이 되었다.
- 마크업이 길다란 클래스 이름으로 비대해졌다.
- 재사용할 때마다 모든 ui 컴포넌트를 명시적으로 확장해야만 했다.
- 마크업이 불필요하게 의미론적이 되었다.
CSS 모듈과 로컬 스코프
SASS나 BEM이 수정하지 않은 문제 중 일부는 언어 논리에 진정한 캡슐화 개념이 없으므로 개발자가 선택한 고유 클래스 이름에 의존해야 한다는 것이였다. 컨벤션보다는 도구로 처리할 수 있을 것 같았다.
이것이 바로 정확히 CSS 모듈이 한 일이다. 로컬 정의된 각 스타일에 의존해 동적으로 클래스 이름을 만들었다. 모든 스타일을 적절하게 캡슐화해서 새로운 CSS 속성을 주입함에 따라 생기는 시각적 퇴행현상을 없애버린 것이다.
React 생태계에서 CSS-모듈은 빠르게 인기를 얻었으며, 이제 기본적으로 많은 React 프로젝트들이 이것을 일반적으로 사용하고 있다. 장점과 단점이 있지만 사용하기 좋은 패러다임이 입증된 것이다.
그러나… CSS 모듈 자체 만으로는 CSS의 핵심 문제를 해결하지는 못한다. 단지 스타일 정의를 지역화하는 방법만을 보여주었을 뿐이다: 한번 선택했던 클래스이름을 다시 선택하지 않는 자동화된 BEM이 있어서 당신이 클래스 네임을 고민할 필요가 없는 것이다(적어도 더 조금만 고민하면 되는)
그러나 이것이 최소한의 노력만으로 예측 가능하고 확장 재사용이 가능한 아키텍쳐에 대한 필요성을 줄이지는 못한다.
이것이 로컬 CSS의 모양이다:
단지 그것이 CSS라는 것을 알 수 있다. 가장 큰 차이는 모든 클래스네임 앞에 유니크한 클래스 이름을 생성하도록하는 :local이 붙는 것이다. 그 유니크한 클래스 이름은 다음과 같다:
.app-components-button-__root — 3vvFf {}
localIdentName 쿼리 파라미터를 통해서 생성되는 글자를 설정할 수 있다. 디버깅이 쉽도록 하는 예를 들면:
css-loader?localIdentName=[path][name]---[local]---[hash:base64:5]
처럼 할수 있다.
이것이 Local CSS Modules의 기본 원리다. 로컬 모듈이 동일한 이름을 사용하더라도 다른 모듈과 동일하지 않을 것이라는 것을 보장하는 자동화된 BEM 표기방법을 제공하는 방법이다. 매우 편리하다.
Styled Components to blend css in JS (fully)
Styled-components는 순수한 시각적 primitives다; 실제 html 태그에 매핑될 수 있으며 자식 컴포넌트들을 styled-component로 감싸는 일을 한다.
다음 코드로 더 설명하는 것이 나을 것이다:
보기만해도 styled component는 굉장히 이해하기 쉬울 것이다. 템플릿 리터럴 표기법을 사용하여 css 프로퍼티를 정의하고 있다는 것은 core styled-compoents 팀이 es6와 css의 모든 파워를 혼합한 것 처럼 보인다.
Styled-components는 기능적, 상태적인 컴포넌트에서 UI를 완전히 분리하고 재사용할 수 있는 매우 단순한 패턴을 제공한다. React Native 혹은 브라우저의 HTML 양쪽 태그 모두를 억세스하는 api를 만드는 것이다.
이것이 Styled Component에 props(혹은 modifiers)를 전달하는 방법이다:
props가 갑자기 각 컴포넌트가 받는 modifier가 되고, css 몇 라인의 출력으로 처리될 수 있음을 알 수 있다. 산뜻하지 않은가?
따라서 스타일을 처리하는데 JS의 모든 기능을 사용하면서 일관성있고 재사용 가능한 상태를 유지한 채로 빠르게 움직일 수 있게 한다.
모든 사람이 재사용하는 Core UI
CSS 모듈이나 Styled Components나 그 자체로는 완벽한 솔루션이 아니라는 것은 꽤 빠르게 명백해졌고, 작동과 확장을 목적으로 하는 몇 가지 패턴이 필요하다. 패턴은 컴포넌트가 무엇인지 정의하는 것과, 로직으로부터 완전히 분리하는 것, 스타일을 지정하는 것 뿐이다.
CSS 모듈을 사용한 컴포넌트의 구현 예제다:
보다시피 팬시한 뭔가가 있지는 않고, 그저 props를 받아서 하위 컴포넌트에 매핑하는 컴포넌트일 뿐이다. 다시 말하자면, props를 children에 전달하는 포장용 컴포넌트일 뿐이다.
다음과 같은 방법으로 컴포넌트를 사용할 수 있다.
styled-components를 사용하여 구현한 비슷한 예제를 살펴보자:
이 패턴이 흥미로운 점은 컴포넌트가 dumb이고 상위 컴포넌트에 매핑된 css 정의의 wrapper일 뿐이라는 것이다. 이 일을 하는 것에는 한 가지 이점이 있다:
기본 UI api를 정의하게 해주므로 이를 스왑함으로 모든 UI가 애플리케이션 전체에 걸쳐 일관성있게 유지되도록 해준다.
이 방법은 디자인 처리와 구현 처리를 완전히 분리시켜서 원한다면 각 처리를 병렬적으로 시작할 수 있다. 피쳐 구현에 포커싱한 개발자와 UI를 갈고닦는 개발자에 대해서 서로 완전히 관심사를 분리할 수 있게 한다.
지금까지는 아주 훌륭한 해결책인것 같다. 내부적으로 우리는 이 문제를 두고 토론을 시작했으며 좋은 아이디어라고 생각했다. 그리고 이 패턴과 함께 또다른 유용한 패턴을 식별하기 시작했다:
Prop receivers
이 패턴은 어떤 컴포넌트로 전달된 props를 리스닝하는 기능을 하므로, 어떤 컴포넌트에든 이 기능을 사용하기 쉽고, 어떤 주어진 컴포넌트라도 재사용성과 가용성을 확장할 수 있는 성배로 만들어준다. modifier를 상속하는 방법으로 생각할수도 있다. 다음 예제가 바로 내가 말하는 바다:
이 방법을 통해 특정 컴포넌트를 위한 각 border를 하드코드할 필요가 없음을 확신할 수 있다. 엄청나게 시간을 절약할 수 있다.
Placeholder / Mixin like functionality
styled component에서는 JS의 풀파워를 사용할 수 있다. 즉 prop receivers 뿐만 아니라 서로 다른 컴포넌트 간의 코드 공유같은 방법으로. 여기 예제가 있다:
Layout Components
우리는 애플리케이션 작업을 할때 처음으로 필요한 것이 UI elements를 레이아웃 하는 것임을 알아냈다. 이를 처리하는 과정에서 레이아웃 목적으로 사용하는 몇몇 컴포넌트를 식별해냈다.
이 컴포넌트들은 종종 구조를 세팅하는 힘든 시간을 보내는 몇몇 개발자들에게 매우 유용함이 증명되었다(css 포지셔닝 테크닉보다 충분히 익숙하지는 않다). 여기 그런 컴포넌트들의 예제가 있다:
width와 height를 props로 받고 horizontal prop도 받아서 스크롤바를 하단에 출력하는 <ScrollView /> 컴포넌트를 볼 수 있다.
Helper components
헬퍼 컴포넌트는 엄청난 재사용을 허용하여 우리의 삶을 간단하게 만든다. 우리의 모든 공통 패턴을 저장한 장소다.
지금까지 꽤 유용했던 헬퍼 몇몇은 다음과 같다:
Theme
테마를 지원하는 것은 애플리케이션 전체에 걸친 1개의 source of truth of values를 가지게 할 것이다. 이는 컬러 팔렛트나 공통 룩앤필과 같은 애플리케이션에서 전체적으로 재사용되는 값들을 저장하는데 유용함이 증명되었다.
장점
- 풀파워의 JS가 우리 손에 들어왔다. 이는 컴포넌트 UI와 풀 커뮤니케이션을 의미한다.
- className을 통한 컴포넌트와 스타일의 매핑을 제거한다.(매핑은 속에서 완료된다)
- 지금까지 중 최고의 개발 경험을 제공한다. 클래스네임과 컴포넌트를 매핑을 생각하는데 들이는 엄청난 양의 시간을 줄인다.
단점
- 야생에서 테스트된 적이 없다.
- React를 위해 개발되었다.
- 아직은 정말 미성숙하다.
- classNames를 사용하거나 arai-labels를 위한 테스팅이 필요하다.
결론
SASS, BEM, CSS 모듈, Styled Components 어떤 기술을 사용하더라도 다른 개발자들이 시스템의 새로운 파트를 가져오는 것이나 시스템을 깨뜨리는 것에 대해 너무 많이 생각하지 않아도 당신의 코드 베이스에 기여할 수 있도록 잘 정의된 스타일링 아키텍쳐를 대체할 수는 없다.
이 접근 방법은 애플리케이션을 적절하게 확장시키는데 주요하다. plain CSS 혹은 BEM을 사용하더라도 중요한 차이점은 각 구현에 필요한 작업량과 LOC다. 전반적으로 보면 styled-components는 거의 모든 React 프로젝트에 잘 맞고, 아직 야생에서 태스트되지는 않았지만 충분히 유망한 스타일링 방법이다.
의견이나 의견, 조언 등이 있으시면 아래에 의견을 남기고 트위터 @perezpriego7을 통해 연락 바란다.
Refact, Ember, Rails, Elixir, GraphQL을 사용하여 멋진 프로젝트에서 작업하고 싶다면 AlphaSights에서 채용 중이다. 채용 직군을 확인하려면 https://engineering.alphasights.com/#positions 를 방문하라.





