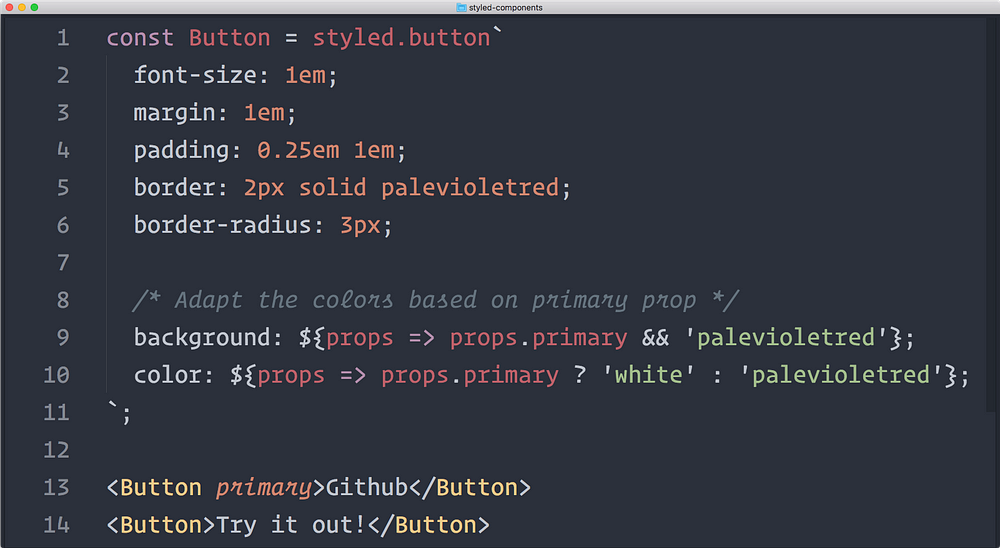
원문보기
May 12, 2016
[8:23 PM] jrajav:: 헤이, <Provider> 컴포넌트가 실제로 어떤 기능인지 궁금해. 완벽히 이해하려는 건 아니고 - 왜 store.subscribe( () => render( <App state={store.getState()} />, document.getElementById('root') ) )처럼 그냥 전달하지 않지?
[8:24 PM] jrajav:: dispatch 함수도 전달하고
[8:24 PM] jrajav:: 다음엔 각 하위 컴포넌트에 상태를 적절하게 나누어서 분할하여 전달하는 거지
[8:25 PM] jrajav:: 만약 모든 컴포넌트가 순수한, stateless 함수형 컴포넌트라면 이 접근방법은 여전히 성능이 좋아야만 하겠지. 안그래?
[9:58 PM] acemarke: @jrajav : 관용적인 Redux 사용법은 약간의 의존성 주입이 일어나. 이상적으로는 컴포넌트와 액션 생성자가 직접 store를 참조하는 일은 없어
[9:58 PM] acemarke: 그게 코드를 더 재사용할 수 있게 하고 테스트 하기도 쉽지
[9:59 PM] acemarke: 이걸 봐바 http://redux.js.org/docs/FAQ.html#store-setup-multiple-stores
[10:00 PM] acemarke: 또한 네가 작성한 스니펫은 App 컴포넌트가 모든 필요한 상태를 아래로 전달하는 것 처럼 보여
[10:00 PM] acemarke: 만약 상태가 하나의 탑레벨 컴포넌트에 둘 수 있을 정도로 작으면 아마도 Redux가 필요할 것 같지도 않네 - 그냥 React의 컴포넌트 상태를 사용해
[10:01 PM] acemarke: 하지만, React Redux에서는 <Provider> 안쪽의 어떤 컴포넌트라도 필요한 state의 조각을 구독할 수 있어. 하위 컴포넌트들이 필요한 데이터를 알고있는 탑레벨 컴포넌트가 없더라도 말이지
[10:25 PM] jrajav:: 맞아 @acemarke, 근데 한편으론 어떤 컴포넌트 트리에서 어떤 데이터를 필요로하는지 알 수 없잖아. 깊이 중첩된 컴포넌트에서 마술처럼 상태조각을 가져가버리는 건 덜 기능적이고 덜 관리가능해 보여
[10:26 PM] jrajav:: 만약 중첩된 컨테이너를 사용해서 상태를 구독해버리면 말이야
[11:56 PM] acemarke: 어.. “마술”이란건 없는데
[11:57 PM] acemarke: connect()를 사용해서 정의된 어떤 컨테이너 클래스라도 필요한 상태 조각을 명확하게 지정할 수 있어
[11:57 PM] acemarke: 여기 전형적인 예제가 있어
[11:57 PM] acemarke: 상태 안에 여러명의 users가 있고
[11:58 PM] acemarke: 탑 레벨의 프레젠테이셔널 컴포넌트를 가지고 있고, LeftSidebar와 RightMainPanel이라는 두개의 프레젠테이셔널 컴포넌트를 렌더링한다고 하자
[11:58 PM] Francois Ward: 내 생각엔 그가 말하는건 폴더 구조를 봤을 때, grep하지도 않고 아무데서나 물건들이 나타나는걸 말하는 것 같아
[11:58 PM] acemarke: LeftSidebar에서는 connected 컴포넌트인 UsersList를 렌더링한다고 하자
[11:58 PM] acemarke: UserItems의 목록을 표시하는 List지
[11:58 PM] acemarke: 아마도 이름이나 몇몇 세부사항을 표시하겠지
[11:58 PM] Francois Ward: 그 모델의 꽤 일반적인 비판이지. Cyclejs/Elm에서는 “모든 것은 맨 위쪽에서부터 아래쪽으로 이어져서 내려온다” 라고 하지. 그건 실용주의 vs 쉽게따라가기/순수성/테스트성의 타협이야.
[11:59 PM] acemarke: 그러고나서, 만약 UserListItem을 선택하기 위해 클릭하면, RightMainPanel에 UserDetails 컴포넌트가 보여지길 바랄거야
[11:59 PM] acemarke: 역시 connected 컴포넌트지 user에 대한 세부 사항을 보는
May 13, 2016
[12:00 AM] acemarke: 하지만 TopLevelComponentㄱ LeftSidebar와 RightMainPanel을 렌더링하지만 그 세부사항에 대해 알 필요는 없어
[12:00 AM] acemarke: 만약 모든 데이터에 대한 책임을 탑레벨 컴포넌트에게 지우고 싶다면 그럴 수 있어
[12:01 AM] acemarke: 하지만 이 시점에서 일반적으로 인정되는 모범사례는 컴포넌트 트리의 하위 부분에 여러 개의 연결 포인트가 있는 것이야 데이터가 실제 필요한 부분에 가깝게 말이지
[12:02 AM] acemarke: 원래 질문에 답하자면 Provider를 사용하는 이유는 하나의 탑레벨 컴포넌트에만 연결 포인트를 두고 그 아래는 pure한 stateless 컴포넌트로 두는 것에 반대하는 것이지
[12:03 AM] acemarke: 오 그리고 @jrajav : 네 질문에 대한 특정한 대답인데, 그게 더 성능이 좋지는 않아
[12:03 AM] acemarke: 하나의 탑 컴포넌트를 연결하는 것은 모든 스토어 변경사항에 대해서 재 렌더링을 할거야
[12:03 AM] acemarke: 그리고 그 하위의 모든 stateless 컴포넌트도 재 렌더링할거야
[12:04 AM] acemarke: 하위 컴포넌트를 여러개 연결하는 것은 서브렌더 트리를 더 작게 만들지
[12:04 AM] acemarke: 그리고 React Redux는 얼마나 많은 연결된 컴포넌트가 실제로 재 렌더링해야하는지에 대한 최적화로 많은 작업들을 해
[12:19 AM] jrajav:: 맞아 @Francois Ward 그게 내가 뜻한 바야
[12:20 AM] jrajav:: connect() 자체의 “마술” 부분이지, 임의의 장소에서 상태를 가져와서 노출시키는 것 말야
[12:21 AM] jrajav:: 그리고 @acemarke 설명해줘서 고마워 - 재 렌더링이 뜻하는 바를 정확히 물어봐도 될까?
[12:22 AM] jrajav:: 네가 말하는 바가 React가 실제로 light DOM에 모든 싱글 컴포넌트를 재 렌더링한다는거야?
[12:22 AM] jrajav:: 아니면 그냥 shouldComponentUpdate에 의해 “숏-서킷”되지 않고 render()함수가 재실행 된다는 거야?
[12:22 AM] acemarke: …반대로?
[12:23 AM] acemarke: 만약 네가 mapStateToProps 함수가 state.some.very.nested.field를 파야한다고 걱정되면 “selector”를 이용해서 상태 트리의 특정 필요 부분을 가져오는 식으로 캡슐화하면 돼
[12:24 AM] jrajav:: 아냐, 나는 React + redux + immutable.js가 더 걱정돼 그리고 상태 오브젝트 전체를 <App /> 컴포넌트에 전달하는 패턴이 하나의 상태 필드만 고쳤을 때도 전체 <App />을 DOM에 재 렌더링하는 결과를 내는 것이 더 걱정돼
[12:24 AM] jrajav:: 혹은 React의 virtual DOM diff를 대부분의 파트에서 실행한다거나 하는 것 말야
[12:25 AM] jrajav:: diffing이 어떤식으로 일어나는지는 정확히는 모르지만 말야
[12:27 AM] jrajav:: 예를들어 <Page1 />과 <Page2 />가 있다고 하고 전체 상태 오브젝트의 서브 프로퍼티인 pageOne을 1로 pageTwo를 2로 전달하려고 해. pageTwo의 중첩된 몇몇 서브 프로퍼티가 변경되서 <Page2 />가 바뀌고, 재 렌더링된다고 하자. pageOne의 어떤 것도 바뀌지 않았기 때문에 <Page1 />은 같은 파라미터와 함께 호출되서 같은 virtual DOM 트리로 결과가 나타나지
[12:28 AM] jrajav:: 나는 모든 React가 최적화되지 않았기 때문에 피할수 있는 모든 render()가 호출된다고는 생각하지 않아 (맞지?) stateless functional 컴포넌트들 말야
[12:28 AM] jrajav:: 하지만 최소한, virtual DOM diffing의 결과에 따라 <Page1 />의 light DOM은 아무것도 갱신되지 않겠지.. 맞지?
[12:29 AM] acemarke: render 함수는 재실행되고 그에 맞는 virtual DOM도 re-diffed 될거야
[12:29 AM] acemarke: 주어진 컴포넌트의 인풋이 아무것도 변경되지 않더라도, 즉 헛된 노력이지
[12:30 AM] jrajav:: 맞아 - 그래도 DOM 업데이트에 비해서 값싼 것이지
[12:30 AM] jrajav:: memoizing 래퍼에 의해 잠재적으로 해결될 수 있고
[12:30 AM] acemarke: 아 잠깐, 네가 쓴걸 좀 읽어볼게
[12:30 AM] acemarke: (wifi를 실행시켜서 약간 연결이 끊기네)
[12:30 AM] jrajav:: 괜찮음
[12:31 AM] jrajav:: 그리고 더 명확히 하자면 light DOM은 “actual DOM”을 이야기한거야
[12:31 AM] jrajav:: (주로 Polymer로 작업할때 shadow DOM 때문에 light DOM이라고 말하곤 하지)
[12:32 AM] acemarke: 이론적으론 맞아
[12:32 AM] acemarke: 하지만 추가적으로 알려줄게 있어
[12:32 AM] acemarke: connect()가 여러가지 편리하게 해주는 것들이 있는데
[12:32 AM] acemarke: 다른 것들 중에서도, 그건 shallow equality check를 하지 mapStateToProps가 리턴한 오브젝트에 대해서 이전에 뭘 리턴했는지랑 말야
[12:33 AM] acemarke: 그래서 컴포넌트가 MSTP로부터 같은 내용을 연달아 리턴하게 된다면 재 렌더링을 넘어갈 수 있어 포장된 컴포넌트의 재 렌더링 말야
[12:34 AM] acemarke: 위쪽에 말야
[12:34 AM] acemarke: 네 Page1/Page2 예제에서
[12:34 AM] jrajav:: 아 그래.
[12:35 AM] acemarke: connect()를 사용하지 않았다고 가정하면, 그리고 직접 shouldComponentUpdate를 구현하지 않았다고 하면, Page2에 관한 상태 트리의 아주 작은 부분이라도 변한다면 Page1 Page2 양쪽과 그 모든 하위 컴포넌트에 대해 적어도 render / diff 사이클을 유발할거야
[12:36 AM] jrajav:: shouldComponentUpdate의 자체 구현에 의한게 네가 말한 memoizing 래퍼 컴포넌트 맞지?
[12:36 AM] jrajav:: 만약 서브컴포넌트를 memoize했다면 VirtualDOM에 대한 diffing을 피할 수 있지?
[12:39 AM] acemarke: data->props 관리하는 것을 추가적으로 해주기 때문에 React Redux의 connect()는 사용하는 것만으로 좋은 성능 향상이 일어나지
[12:39 AM] acemarke: 아.. 아니 보통 SCU는 prop 동등성 체크를 하지
12:41 AM] jrajav:: 음 shallow comparison은 보통 memoizing 래퍼들이 할 건데
[12:41 AM] jrajav:: 난 shouldComponentUpdate가 render()가 같은 컴포넌트를 리턴하는 것과 같은 방식으로 동작하는 건지 알지 못하겠네
[12:41 AM] acemarke: 일반적으로 SCU는 this.props와 nextProps에 대해 shallow 동등성 체크를 해
[12:41 AM] acemarke: 이상적으로는
[12:41 AM] acemarke: 메모이제이션은 안하지
[12:42 AM] acemarke: SCU는 컴포넌트를 리턴하지 않아
[12:42 AM] acemarke: boolean을 리턴하지
[12:42 AM] jrajav:: 그럼 stateless functional 컴포넌트는 중복을 막지 못한다는거야?
[12:42 AM] acemarke: 그건 말 그대로 “이봐 컴포넌트, 여기 네 props가 이렇게 들어왔어. 재 렌더링하길 원해? 예/아니오”
[12:43 AM] acemarke:
shouldComponentUpdate(nextProps) {
// single-field example. extrapolate for more props, or do all of them
return this.props.someField !== nextProps.someField;
}
[12:43 AM] acemarke: 아니
[12:44 AM] acemarke: 네가 React 라이프사이클 메서드를 원한다면 React.createClass()나 MyClass extends React.Component를 사용해야해
[12:44 AM] acemarke: 지금으로써는 functional stateless components는 간편하고 명확할 뿐이지
[12:45 AM] acemarke: 어떤 성능 최적화도 하지 않아(문서에서는 곧 할거라고는 하지만), 효과적으로 재 렌더링이 일어나지 않게할 방법이 없으므로 성능 손실이 발생하지
[12:46 AM] acemarke: 즉, connect()에 어떤 타입이라도 전달한다면 이득을 볼수 있다는 거지
[12:47 AM] acemarke: 왜냐면 그건 네 “진짜” 컴포넌트를 랩핑하는 것이니까
[12:47 AM] jrajav:: 이론적으로는 상태를 추출하지 않아도 connect()를 사용할 수 있다는거네?
[12:48 AM] jrajav:: 그리고 그건 SCU의 shallow 프로퍼티 최적화(Immutable로 충분한)를 해줄 거라는 거고
[12:48 AM] jrajav:: 혹은 내 고차 컴포넌트 함수를 비슷하게 써도 되고
[12:49 AM] jrajav:: 하지만 stateless function에 대해서는 최적화 방법이 없다는 거지
[12:50 AM] acemarke: 어떤 도움이 된건가?
[12:50 AM] jrajav:: 아직 명확하지 않은 것 한 가지가 있어. 모든 것을 virtual DOM으로 재 렌더링하는 비용을 제거하고 싶어
[12:50 AM] jrajav:: virtual DOM diffing은 실제 DOM을 업데이트하는 것을 대부분 막아주지 맞지?
[12:51 AM] jrajav:: 그래서 <Page1 />의 어떤 실제 DOM 부분도 절대 변하지 않는다는 거지? 최적화되지 않은 stateless 컴포넌트라도 예를 들자면말야
[1:00 AM] acemarke: 기본적으로, 맞아
[1:02 AM] acemarke: 맞아 확실해
[1:02 AM] acemarke: 아무 필요없는 비교를 하는 데 꽤 많은 CPU 싸이클을 낭비하겠지
[1:03 AM] acemarke: 컴포넌트가 몇개 없거나 상대적으로 Redux Store의 크기가 작다면 신경쓸 필요 없어
[1:04 AM] acemarke: 이전 시대의 격언인 “일단 동작하게 하고, 그다음 올바르게 만들고, 그다음 빠르게 하라”는 말로 충분하지
[1:06 AM] acemarke: 반대로 꽤 많은 컴포넌트가 필요하다는 것을 알고 있고, 액션도 많다면(특히 controlled input을 store를 업데이트하는 데 사용한다면), 정말 이런 낭비를 막을 필요가 있을거야
[1:07 AM] acemarke: 잘 시간이 지났네. 도움이 됐길 바라 :)
[1:07 AM] jrajav:: 그래, React가 stateless 컴포넌트를 최적화 할때까진 connect()나 memoizing 레이어를 이용해야 한다는 거네
[1:07 AM] jrajav:: 맞아 엄청 도움됐어 @acemarke
[1:07 AM] jrajav:: 시간을 많이 써줘서 고마워
[1:08 AM] jrajav:: (그런데 실제 memoizing이 아니라, React-short-circuiting이나 뭔가 있지 않나)
[9:30 AM] jrajav:: @acemarke https://github.com/acdlite/recompose 의 pure() 함수가 react-redux의 connect()같은 일을 한다는것을 알아냈어
[9:30 AM] jrajav:: 그럼 stateless 컴포넌트에 대해서 connect()를 선호하는 이유가 더 있을까?
[9:31 AM] jrajav:: 만약 통과하는 props에만 의존한다면?
[9:31 AM] jrajav:: 다른 성능 최적화를 제공한다거나 하나?
9:49 AM] acemarke: 맞아, 조금 더 해. 네가 말하는 접근법을 감안하면 아마도 recompose도 사용할 것 같군. 더 명확한 의도로
[9:52 AM] acemarke: (분명히, 난 아직 네가 connect를 여러 곳에서 사용하는 걸 반대하는 것 같아)
[10:06 AM] jrajav:: 난 그냥 더 functional한 방법을 선호할 뿐이야. 데이터 의존성이 명확니까, 합성이나 테스팅도 엄청 쉽지.
[10:07 AM] jrajav:: 내가 더 봐야할게 뭐지? 네가 말한 방식이 recompose가 제공하는 것들에도 있나?
[7:58 PM] acemarke: @jrajav : connect()를 사용하면 내장된 두 가지 최적화를 제공하고 더 많은 최적화를 할 수있는 공간을 제공해. 최근의 스토어 변경이 컴포넌트에 영향을 미치는지 알기 위해서 mapStateToProps가 리턴하는 오브젝트에 대해서 shallow-comparison을 하지. (부모로부터 직접 전달되는 prop은 아니고); 그리고 잘 알려지지 않은 최적화인데 map/dispatch/merged props 중 어떤 것도 변경되지 않은 경우에 React.createElement가 정확히 같은 인스턴스를 반환하는 거야; 그리고 이 모든 것 위에 너만의 shouldComponentUpdate를 추가로 구현할 수도 있어.
Dan은 connect()의 소스코드 대부분을 휼륭한 비디오 코스를 통해서 그게 어떻게 구현되었는지 알려줬지. 지금은 코드가 조금 진화했겠지만, 여전히 좋은 정보야. 여기 그 비디오 링크야 https://youtu.be/VJ38wSFbM3A.
[9:11 PM] jrajav:: @acemarke 그래서 만약 우리가 주입된 상태나 dispatch를 사용하지 않고 그저 immutable.js props로 모든 것을 명시적으로 전달한다면, connect()는 recompose의 pure()가 하는 일 외에 아무 것도 추가하지 않는다는 거지?
[9:11 PM] jrajav:: 맞아?
[9:11 PM] jrajav:: 왜냐면 immutable.js props만을 가지고서 shouldComponentUpdate를 shallow-compare하기면 이 모든 것(pure()가 하는 것)을 덮을 수 있으니까
[9:13 PM] acemarke: 거의, 맞아
[9:38 PM] acemarke: 흠. 이봐, @jrajav. 이 모든 것 말고 고려해야 할 하나가 뭔지 알아? 컴포넌트 트리를 어떻게 두었냐에 따라 이 shouldComponentUpdate의 모든 이득을 취하지 못할 것이라고 생각해.
[9:38 PM] acemarke: 만약 수동으로 위에서 아래로 모든 props를 전달하려고 하면, 트리 윗부분의 몇 개의 컴포넌트가 항상 다시 렌더링될거라는 것을 의미하지
[9:38 PM] acemarke: 아래쪽 근처에 있는 것들은 그렇지 않겠지만
[9:39 PM] acemarke: 하지만 많은 props를 하위 컴포넌트들에게 위임하는 것들은 마찬가지야
[9:39 PM] acemarke: 항상 깊게 중첩된 하위 컴포넌트가 어떤 props를 필요로 하는지 추적해야 하고 A > B > C > D > E로 전달될 수 있도록 생각해야만 해
May 14, 2016
[1:24 AM] jrajav:: 루트로부터 리프까지 경로가 모두 재 렌더링해야할 필요가 있다는 것은 이치에 맞네. 그게 정확이 무슨 일이 일어나고 있는지 반영하는게 아닌가? 어떤 방식의 조직화가 그런걸 피할 수 있지?
[1:27 AM] jrajav:: 그리고 맞아 @acemarke 나는 그 props들을 추적하는 것이 얼마나 번거로운지 알아. 개인적으로는 다음과 같이 생각하고 있어: D가 E를 포함하고 E는 렌더가 필요한 부분이라고 하자. 그러면 D가 E가 필요로 하는 프로퍼티를 필요로하는게 이치에 맞아. 왜냐면 그 프로퍼티는 실제로 D가 렌더링 될 때 필요한 프로퍼티기 때문이지. 그리고 다른 것들도 마찬가지겠지… 나는 오히려 컴포넌트의 함수 시그니처에 렌더를 목적으로 필요한 파라미터를 정확히 요구해야하는 문제라고 봐. 컴포넌트가 마술처럼 스토어의 임의 장소에서 상태를 가져오는 것이 아니라 말이야. 내게는 전역 변수와 싱글톤 클래스로 state를 갖고 올 수 있는게 편할 수 있지만, 코드는 어디서 그것들이 오는지 추론하기 힘들어지고, 테스트하기 어렵고, 검증하기 어렵고, 오류가 발생하기 쉬울 거야.
[1:28 AM] jrajav:: 그리고 react/redux에서는 함수형 패러다임을 사용하는 것처럼 보이는데도 그런 컨테이너/ 컴포넌트를 사용하는 방법이 “모범 사례”라는 것이 나에게 매우 혼란스러워.
[11:37 AM] acemarke: @jrajav : 내가 봤을때는, “container” 패턴이 몇 가지 장점을 갖고 있어. 우선, 개념적 유형에 따른 분리를 허용하지. 그런 방식으로 바라본다면 말야 - 컴포넌트가 레이아웃과 조직화에 중점을 두는 것들과 컴포넌트가 데이터를 가져오는 데 책임을 갖는 것들 (Redux store루부터든지 서버로부터든지 등등).
[11:41 AM] acemarke: 둘째, 성능 향상을 얻을 수 있어. 전체를 탑-다운 하는 방법에선 몇몇 컴포넌트는 항상 강제로 재렌더링될 수밖에 없어. 대부분의 layout 중점의 presentional 컴포넌트는 아마도 전혀 재 렌더링되지 않겠지, 그리고 connect()를 사용하는 것은 효율적으로 트리 형태의 새로운 업데이트를 시작할 수 있을 거야. 특히 컨테이너 컴포넌트가 부모로부터 직접 전달받는 props가 없다면 말이야. 그래, 스토어가 업데이트되면 업데이트는 mapStateToProps가 신경쓰는 어떤 값 이외의 변경에 대해서는 변경되지 않을거야 그럼 컴포넌트는 재 랜더링을 건너뛰게 되고 그 하위 서브트리도 마찬가지지. 간단히 승리한 거야.
[11:43 AM] acemarke: 셋째, connected 컴포넌트는 필요한 데이터를 바로 그곳에서 가져오기 때문에 실제 데이터의 흐름을 보다 쉽게 추적할 수 있게 해. 더 적은 수의 레이어가 필요하기 때문이야. 내 UserListItem에 뭔가 문제가 생겼음을 알았을 때 TopLevelComponent > MainLayout > LeftSidebar > UserList > UserListItem을 통과해가면서 추적하는 것 보다 그냥 상위의 UserList를 보면 되기를 바라지
[11:44 AM] acemarke: 넷째, connected 컴포넌트는 애플리케이션의 컨텍스트 내에서 더 많은 재사용성을 갖지 - LeftSidebar를 BottomPanel로 옮기기로 결정했다면 그냥 props가 최상위 컴포넌트에서 내려오는 흐름을 신경쓰지 않고도 그냥 옮기면 되는거야
[11:46 AM] acemarke: 다섯째, connected 컴포넌트를 테스팅하는 것에 대한 충고는 connected 버전의 컴포넌트를 default로 export하고 “plain” 컴포넌트를 named export한 다음 unconnected 버전의 테스트를 테스트하는 거야. 네가 신경써야 할 것은 props와 lifecycle에 어떻게 반응하는지 뿐이지. 어떻게 props를 얻는지는 문제가 되지 않아. 따라서, 넌 그저 몇몇 props를 테스트 코드에 넣고 거기서 행동을 검증하면 되고, 아마도 mapStateToProps 함수도 원한다면 테스트할 수 있지만, connect()가 올바르게 mapStateToProps를 호출하기만을 가정하면 되는거야. 필요할 때는 뭔가 바뀌었을 때 그 props를 컴포넌트에 전달하면 돼.
[11:50 AM] acemarke: 여섯째: 맞아, Redux가 “전역 변수” 라는 측면이 있지만, 반대로, 관용적인 Redux 코드는 절대로 실제 직접 레퍼런스하지 않아. 모든 것은 의존성 주입으로 얻어내지. connect()는 스토어로부터 props를 전달하고 dispatch()에 대한 참조를 제공하고 미들웨어는 dispatch() 및 getState()를 주입하고, 썽크와 같은 실제 미들웨어들은 액션 생성자에도 이것들을 주입하지. 실제 앱 코드의 어디에서도 직접 스토어를 레퍼런스하지 않아. 스토어를 생성하는 두 줄을 제외하고는. 그리고 바로 <Provider>에 전달하지. 그게 redux-mock-store가 테스팅을 실제로 가능하게 하는 방법이야
[11:50 AM] acemarke: 마지막으로, 조금 헷갈리네: “containers” vs “functional”에 대한 네 걱정은 뭐지?
[11:52 AM] acemarke: 궁극적으로 보면 좋은 아키텍쳐의 구성하는 것이 무엇인지에 대한 조금 다른 철학을 가지고 있는 것처럼 들리네. 난 그저 각자의 관점에서 다른 점이 무엇인지 이해하려고 시도하고 있어.
[2:03 PM] Francois Ward: ““다섯째, connected 컴포넌트를 테스팅하는 것에 대한 충고는 connected 버전의 컴포넌트를 default로 export하고 “plain” 컴포넌트를 named export한 다음 unconnected 버전의 테스트를 테스트하는 거야. 네가 신경써야 할 것은 props와 lifecycle에 어떻게 반응하는지 뿐이지.”
[2:04 PM] Francois Ward: 조심스럽게 저것에 대해 말해보면, 그건 간단하지 않아.. 만약 dumb 컴포넌트가 connected 컴포넌트를 가지고 있다면 어떻게든 반드시 스토어를 제공해야해. 아니면 connected 컴포넌트를 목킹하든지. Jest의 문제가 아니고, shallow render를 쓸때도 그래.
[2:04 PM] Francois Ward: 하지만 항상 옵션인 것은 아니지.
[2:04 PM] acemarke: 맞아 아마도 문서에 경고해야할 몇가지 점이 있지
[2:04 PM] Francois Ward: connected 컴포넌트를 children으로 가지는 것은 뒤쪽에 고통스러움이 있지. 그건 타협이야. 하지만 “어디서든 연결하세요, 무료입니다!”라고 할 건 아니지
[2:05 PM] Francois Ward: 강력한 이점이지만. 또한 높은 비용을 수반하지.
May 15, 2016
[11:39 AM] jrajav:: @acemarke 매우 자세한 답변 고마워! 그리고 맞아. 네가 언급했듯이 모범 사례에 대한 의견차이일 뿐이라고 생각해. 너는 컴포넌트가 어떻게 자신의 프로퍼티를 글로벌 상태(혹은 그것에 가까운 부모)에서 가져오는지 아는 것이 컴포넌트를 재사용하기 쉬게 해주는 이유라고 하고, 나는 컴포넌트 레벨에서는 그것을 인정해. 하지만 임의의 지점에서 글로벌 상태를 다루는 것은 여러 컴포넌트의 조합을 만들고 앱 자체에 대해 추론하기 어렵게 만들고 더 조합하기 어렵게 만들어서(함께 퍼즐을 맞추는 것처럼) 더 에러를 유발한다고 봐. 데이터 의존성에 대해 명시적으로 선언하는 추가 작업(이 경우에는 파라미터를 수동으로 아래로 전달하는 작업)은 그런 것들을 피할 수 있는 좋은 작업이야. 애플리케이션을 더 단순하고 관리가능하게 만들어 주는 거지. 적어도 그게 내가 보는 방법이야.
[11:41 AM] jrajav:: @acemarke 또한, React가 항상 presentaion 계층으로, 스토어에 대해서는 전혀 아는 바 없고, 모든 컴포넌트를 “dumb”, pure하고 실제 라이프사이클을 갖지않게 강제하지. - 라이프사이클은 그저 그들의 input 중에 함수일 뿐이야 - 그게 개발, 테스트, 재사용을 훨씬 쉽게 만들지
[11:42 AM] jrajav:: 그리고 이게 무슨 뜻인지 물어봐도 될까? (edited)
[11:42 AM] jrajav:: > 둘째, 성능 향상을 얻을 수 있어. 전체를 탑-다운 하는 방법에선 몇몇 컴포넌트는 항상 강제로 재렌더링될 수밖에 없어. 대부분의 layout 중점의 presentional 컴포넌트는 아마도 전혀 재 렌더링되지 않겠지, 그리고 connect()를 사용하는 것은 효율적으로 트리 형태의 새로운 업데이트를 시작할 수 있을 거야. 특히 컨테이너 컴포넌트가 부모로부터 직접 전달받는 props가 없다면 말이야. 그래, 스토어가 업데이트되면 업데이트는 mapStateToProps가 신경쓰는 어떤 값 이외의 변경에 대해서는 변경되지 않을거야 그럼 컴포넌트는 재 랜더링을 건너뛰게 되고 그 하위 서브트리도 마찬가지지. 간단히 승리한 거야.
[11:44 AM] jrajav:: 내가 이해한 바로는, 전체 서브트리가 쓰는 props를 조합한 shouldComponentUpdate를 가지고 있으면 모든 파라미터가 동일할 때(아마도 deep 오브젝트를 핸들링하기 위한 Immutable.js같은 것으로), 서브트리가 렌더되지 않을 것이기 때문에 다른 방법론과 어떻게 다른지 이해할 수 없어
[11:48 AM] jrajav:: 그리고 네 질문에 직접 담변하자면, “containers” vs “functional”에 대한 내 걱정은 내 원칙을 따르면 React는 항상 presentation layer여야 해. 하나의 큰 함수지 상태를 적절한 UI로 내놓는 - <App /> 그 자체를 포함하는 거야
[11:50 AM] jrajav:: 그리고 모든 반대의견에 감사해! @acemarke 난 분명히 선입견을 가지고 있지만 React에 대해선 입문자고 조심스러운 뉘앙스를 가져야한다는 것을 고려하지 못했어. 이것은 내게 매우 가치있어.
[11:52 AM] acemarke: @jrajav : 물론, 합리적이고 기술적인 의견과 토론은 항상 가치있지 :)
[11:53 AM] acemarke: 어디보자. 네 코멘트를 하나하나 보면:
[11:54 AM] acemarke: 내 경우에는 일반적으로 내가 읽었던 수많은 토론과 내 앱이 필요로하는 특별한 니즈에 영향을 받았어
[11:55 AM] acemarke: 예를 들어 Redux 초창기에 Dan Abramov의 충고 같은거지 connected 탑 컴포넌트, 혹은 아마도 최상위 몇몇 컴포넌트의 connected에 대한 것
[11:57 AM] acemarke: 하지만 시간이 지나서 그 조언은 확실히 바뀌었어, 이제는 이치에 맞으면 깊은 곳 어디든지 연결하라는 것이지. 사실, 그의 MobX와 Redux 벤치마트를 위한 최근의 최적화 과정에서 그는 “10K 항목이 있는 List” 시나리오에서는 부모 리스트가 10K 아이템에 대한 ID를 가져오고, ID를 자식에게 전달하고, ListItems 자체도 항상 연결하여 자신들의 업데이트에 대해 책임을 지게 하는 것이였어. 그렇게 하면 하나의 목록 항목을 업데이트해도 ID 셋트가 수정되지 않으므로 상위 목록을 다시 렌더링할 필요가 없게되는 것 등이지.
[12:00 PM] acemarke: 또다른 생각은 “React는 그저 view 계층일 뿐이다” 라는 것은 사실이지만, 여기서 문제는 우리가 data 계층과 view 계층을 연결하는 방법을 알아내려 한다는 것이야. 일반적인 connected 컴포넌트는
각자가 mapStateToProps를 정의하고 있고 plain 컴포넌트는 같은 파일의 바로 옆에 위치하지, 그리고 디폴트로connect(mapStateToProps)(MyComponent)를 익스포트하지. 그래서 connected 컴포넌트에 필요한 데이터가 무엇인지 쉽게 파악할 수 있게 되는 거야
[12:01 PM] acemarke: 또한 여러개의 connected 컴포넌트가 있는 경우에도 전체 UI는 여전히 “상태에 대한 함수”라고 생각해
[12:01 PM] acemarke: 어디보자. 트리 성능…
[12:01 PM] jrajav:: 이 경우의 “재 렌더링”은 리스트 요소가 모든 리스트아이템에 대해 반복할 필요가 있다는 것을 의미한다. SCU에 그 대부분을 전달하여 알아내려고, 맞지?
[12:02 PM] acemarke: 맞아
[12:02 PM] acemarke: 부모 렌더 -> 자식들의 SCU 확인 -> 자식들은 재 렌더되거나 안되거나한다
[12:02 PM] acemarke: 하지만 요점은 SCU가 문자 그대로 동일하더라도 불린다는 거다.
[12:03 PM] jrajav:: 맞아
[12:03 PM] jrajav:: 하지만 SCU가 그저 Immutable.js의 동등성 체크라면, 그저 single === 체크일 뿐이지 않나?
[12:03 PM] jrajav:: 함수의 호출 요소가 있지만 그건 그리 비싸지는 않다.
[12:03 PM] acemarke: 어쨌든 props의 필드당 한 번이다.
[12:04 PM] jrajav:: 맞아
[12:04 PM] jrajav:: 하지만 알겠어 렌더링 할 때 서브트리를 건너뛸 수 있는지 말야
[12:05 PM] acemarke: 네가 물어본 서브트리에 대한 내 관점을 정확히 하려는데 뭘 좀 알려줘
[12:06 PM] acemarke: 내가 이해하기로는 “하나의 탑레벨 컴포넌트가 모두를 지배한다” 시나리오에서, 기본적으로 const mapStateToProps = (state) => state;를 하기만 하면 되는데
[12:06 PM] jrajav:: 네가 말하려는 걸 전부 확신할 수 없어
[12:06 PM] jrajav:: 조금 더 말하자면 mapStatetoProps가 아무데도 없는거야
[12:06 PM] acemarke: 음, 스토어에서 뭔가를 가져가서 사용하는 누군가 말이지…
[12:07 PM] acemarke: 혹은 동등한 뭔가…
[12:07 PM] jrajav:: <App dispatch={store.dispatch} state={store.getState()} />(edited)
[12:07 PM] acemarke: 맞아 그게 실제 connect() 호출없이 connect() 하는 방법이지
[12:08 PM] acemarke: 대충 네가 하려는걸 추측할수 있어:
[12:08 PM] jrajav:: 차이점은 이 하나의 루트 엘레멘트만 상태에 접근할 수 있다는 거야
[12:08 PM] acemarke: 그래 connect(state => state)(App) 이랑 같은거지
[12:09 PM] jrajav:: 물론, 하지만 어느쪽이든 간단하다면 명백하고 명시적인 방법이 더 바람직하지
[12:09 PM] jrajav:: 한편으로 넌 state={store.getState()}를 한번만 수행하는 데다가 추상화 함수를 사용하는거야
[12:09 PM] acemarke: 맞아. 아무튼, 요점은, 탑레벨 컴포넌트가 항상 모든 상태를 가져오는 거야
[12:09 PM] jrajav:: 정확해
[12:09 PM] acemarke: 좋아. 내가 좋아하는 어떤 가설적인 앱 구조를 한번 보자
[12:10 PM] jrajav:: Todo? ??
[12:10 PM] acemarke: LeftSidebar랑 RightMainPanel같은 거(edited)
[12:10 PM] jrajav:: 오
[12:10 PM] acemarke: 아니. TODO는 더이상은 네이버….
[12:11 PM] acemarke: 그리고 왼쪽 사이드바가 CurrentUserInfo 컴포넌트랑, ListOfThings 컴포넌트를 보여준다고 하자
[12:11 PM] acemarke: 네가 목록에서 ThingListItem을 선택하면, MainPanel은 그 Thing의 세부정보를 보여줄거야
[12:11 PM] acemarke: 네가 수정할 수 있도록
[12:12 PM] acemarke: 우리 상태는 이렇게 보이겠지 : { currentUser: {}, things : { byId : {}, order : [] }, thingBeingEdited : {} }
[12:13 PM] acemarke: 지금까진 괜찮지?
[12:13 PM] jrajav:: 그래 난 잘 따라가고 있어
[12:14 PM] acemarke: 오 아마도 currentSelectedThingId 필드가 있을 수 있지
[12:14 PM] acemarke: 아마도
[12:14 PM] acemarke: 어떤 순서로 동작하는지 조금만 더 생각해볼게
[12:14 PM] jrajav:: 문제없어
[12:15 PM] acemarke: 사용자는 이미 로그인했다고 하자, 그리고 데이터도 가져왔고, currentUser와 things는 적절히히 채워져있어.
[12:16 PM] acemarke: 그래서 ThingList는 ThingListItems를 모두 표시하지
[12:17 PM] acemarke: 그래서 ThingListItem #1을 선택하여 클릭하고, {type : SELECT_THING, payload : {id : 1} }를 dispatch 하는거야
[12:17 PM] acemarke: 리듀서는 thing.byId[1]의 값을 thingBeingEdited에 복사하고
[12:18 PM] acemarke: 그리고 RightMainPanel에 있는 폼들에게 이 값을 전달하길 원하지
[12:19 PM] acemarke: 그래서, TopLevelComponent는 <RightMainPanel thingBeingEdited={state.thingBeingEdited} />를 렌더링하고, 그건 다시 <ThingEditForm thingBeingEdited={this.props.thingBeingEdited} />를 렌더링하지
[12:19 PM] acemarke: ThingEditForm은 input 여러 개를 렌더하고
[12:20 PM] acemarke: controlled input이라고 가정할게
[12:20 PM] jrajav:: Controlled input이 그들의 값을 상태에 반영하는 걸 의미하는거야?
[12:20 PM] acemarke: 기술적으로 다른 방법이야 - 그들의 값이 상태에서 나오는 거야
[12:21 PM] acemarke: “uncontrolled” input은 사용자가 조작하게 두는거야, 값은 브라우저 자체에 의해서 정상적으로 저장되며, 특정 시점(양식 제출 같은)에 실제 input 엘레멘트에 값을 요청하는거지
[12:22 PM] acemarke: “controlled” input은 항상 모든 입력에 대해 “value” prop을 지정하는 거야. 항상 그 값을 사용하도록 강제하지
[12:22 PM] acemarke: 즉 onChange 핸들러를 지정하고, 이벤트에서 새 값을 보고, 어딘가에 상태를 넣고, 새로 승인된 값으로 다시 렌더링해야해
[12:24 PM] acemarke: 그래. 이제 "Thing #1"의 값을 내 커서가 있는 “Thing Name”에 넣어야 하지. 그리고 타이핑을 시작해
[12:24 PM] acemarke: “asdf”를 "Thing #1"의 끝에다 추가했어
[12:25 PM] acemarke: 각 키 입력은 onChange 핸들러를 트리거하지
[12:25 PM] acemarke: 시나리오 목적상 이건 컴포넌트 상태가 아니라 Redux state에 저장하고 있다고 가정하자
[12:26 PM] acemarke: 그래서 onChange 핸들러는 첫 타이핑에 {type : EDIT_THING_FIELD, payload : {name : “Thing #1a”} } 를 dispatch 하겠지
[12:27 PM] acemarke: thingBeingEdited 리듀서는 thingBeingEdited.name 필드를 새 값으로 업데이트 할테고
[12:27 PM] acemarke: 그래서 thingBeingEdited.name, thingBeingEdited, 그리고 state까지 모두 새로운 레퍼런스지
[12:27 PM] acemarke: 지금까지 시나리오는 명확하지?
[12:28 PM] acemarke: (다시, 내 머리 꼭대기에서 이걸 만들면서, 망치지 않기를 바라고 있어 :))
[12:28 PM] jrajav:: 맞아 지금까진 명확해
[12:28 PM] jrajav:: 그리고 네가 뭘 하려는건지 보기 시작했어 ??
[12:28 PM] acemarke: 그래서. TopLevelComponent는 새 state 레퍼런스를 갖게되지.
[12:28 PM] acemarke: 재 렌더링을 할거야:
[12:30 PM] acemarke:
render() {
const {state} = this.props;
return (
<div>
<LeftSidebar currentUser={state.currentUser} things={state.things} selectedThingId={state.selectedThingId} />
<RightMainPanel thingBeingEdited={state.thingBeingEdited} />
</div>
)
}
[12:30 PM] acemarke: RightMainPanel, ThingEditForm, 그리고 “name” 인풋이 명백히 재 렌더링 되지
[12:31 PM] acemarke: LeftSidebar도 재 렌더링을 시도하겠지
[12:31 PM] acemarke: 이 시점에서 SCU가 나머지 컴포넌트에 얼마나 구현됬나하는 질문이 있지
[12:32 PM] acemarke: 이론상, LeftSidebar는 순수한 presentational 컴포넌트야
[12:32 PM] acemarke: CurrentUserDetails와 ThingList만을 신경쓰는거지
[12:32 PM] jrajav:: controlled input을 사용하면 양쪽다 순수 presentational 아니야?
[12:32 PM] acemarke: ?
[12:33 PM] jrajav:: RightMainPanel도 말이야
[12:34 PM] acemarke: 응 맞아. 시나리오에서 또하나의 버금가는 요점은, 내 생각엔, 상태 변화가 실제로 하나의 작은 input에만 “영향”을 주는 거지, RightMainPanel의 깊은 곳에 묻혀있는 인풋말야
[12:34 PM] acemarke: 하지만, 순수하게 탑-다운으로만 이 키입력을 처리하기 때문에 LeftSidebar도 재 렌더링을 시도할 거라는 거지
[12:34 PM] jrajav:: 맞아
[12:34 PM] acemarke: 이제, LeftSidebar의 SCU 구현을 했다고 하자
[12:35 PM] acemarke: 아직 작업은 끝나지 않았지
[12:35 PM] jrajav:: 음
[12:35 PM] jrajav:: 만약 모든 것이 실제로 pure dumb 컴포넌트라면
[12:35 PM] jrajav:: 그리고 우리가 Immutable.js를 모든 상태 트리에서 사용하고 있다면
[12:35 PM] jrajav:: 그리고 모든 dumb 컴포넌트를 recompose의 pure()로 감쌌다면
[12:35 PM] jrajav:: 아마도 꽤 잘 동작하겠지, 그렇지?
[12:35 PM] jrajav:: 어떤 추가 코드를 작성하지 않아도(pure() 호출을 제외하고), LeftMainSidebar는 SCU가 잘 동작할테고 재 렌더링되지 않을거야t re-render
[12:36 PM] acemarke: 모든 컴포넌트에 대해 그렇게 했다면, 대부분, 그렇지
[12:36 PM] acemarke: 자 시나리오를 조금 뒤집어보자
[12:36 PM] acemarke: TopLevelComponent, LeftSidebar, RightMainPanel이 100% presentational 컴포넌트고 연결되지 않았다면
[12:36 PM] acemarke: CurrentUserDetails, ThingsList, ThingEditForm는 연결되었고 말이야
[12:37 PM] acemarke: 각각은 간단한 mapStateToProps를 갖고 있겠지 탑레벨의 상태에서 적절한 부분을 가져오기 위해 말이야
[12:37 PM] acemarke: 다시 한번, Name 필드에 "Thing #1"에 커서를 두고 “a”를 타이핑해보자
[12:38 PM] acemarke: edit 액션이 디스패치되고 thingBeingEdited.name이 업데이트되고, store가 구독자들에게 알리겠지
[12:38 PM] acemarke: CurrentUserDetails의 mapStateToProps가 재실행되서 {currentUser : state.currentUser}를 리턴할거야
[12:39 PM] acemarke: connect()가 shallow-compare하겠지 이전 리턴값과 이번 리턴값을, 그리고 변하지 않았으니 재 렌더링을 건너뛸거야
[12:39 PM] acemarke: ThingsList도 마찬가지고
[12:39 PM] acemarke: ThingEditForm은 thingBeingEdited가 변경된걸 알았으니 재 렌더링 할거고
[12:39 PM] acemarke: 하지만 TopLevelComponent, LeftSidebar, RightMainPanel은 결코 아무 일도 하지 않을거야
[12:40 PM] acemarke: 알지도 못하고 신경도 안쓰니까, 상태의 나머지 부분에 대해서는 전혀.
[12:40 PM] jrajav:: 여기서 요점이 명확히 드러났네, 하지만 - 하나의 선형적인 비교 연산을 또다른 것과 트레이드하고 있는거 아닌가?
[12:40 PM] jrajav:: 나는 connect()’ed 집합이 더 작아질 수 있다고 주장하는 걸 알았어
[12:41 PM] jrajav:: 하지만 상태 트리가 잘 조직되어 있더라도, UI는 비슷하지 않을 수도 있어
[12:41 PM] acemarke: 맞아, 전채 의도와 행동은 크게 다르지 않을 수 있지
[12:42 PM] jrajav:: 이 경우에는 거의 동일하지만 - 양쪽 다 “실제” 재 렌더링에 대한 3번의 비교를 수행하는 함수가 있는 것 처럼 보이네
[12:42 PM] acemarke: 하지만 UI의 중첩 방식에 따라, 얼마나 데이터를 가졌냐에 따라, 중간 계층의 숫자를 확실히 줄일 수 있어
[12:43 PM] jrajav:: 하지만 중간 계층의 숫자를 많은 컨테이너 컴포넌트로 절충하고 있잖아
[12:43 PM] acemarke: 네가 말했듯이, SCU로 모든 레이아웃스러운 컴포넌트를 명시적으로 태그할지 여부에 대한 질문이야
[12:43 PM] acemarke: props 관리에 대한 거래지
[12:45 PM] acemarke: 개인적으로는, 타이핑 수를 줄이고 성능을 동일하게 유지하며 추적할 데이터 흐름이 적어지지
12:45 PM] jrajav:: 하지만 그건 명시적이지 않잖아 우리가 recompose의 pure()에 의존한다면 말이야
[12:46 PM] jrajav:: 그걸 기억해야 할 필요가 있어…
[12:47 PM] acemarke: 맞아 그게 내가 의미한 바야. 실제로 각 컴포넌트 정의에 포함시켜야 해
[12:47 PM] jrajav:: 맞아
[12:48 PM] acemarke: 자 이제 내 생각에 영향을 미치는 내 앱에 대한 일반적인 설명이야
[12:48 PM] acemarke: 몇 년 전에 GWT로 작성한 앱을 재작성한 거지
[12:50 PM] acemarke: 기본적으로 3D 지구를 사용한 지도 플래닝 툴이야, 사용자를 지구와 상호작용할 수 있게 하지. 왼쪽 창에는 프로젝트의 모든 항목이 있는 몇몇 버튼과 트리뷰가 있고, 아래쪽 창에는 트리의 각기 다른 데이터 유형에 대한 속성을 보여주는 탭이 있어. 데이터 항목들은 트리에 보이고, 폼을 통해 보여지고 수정될 수 있지, 그리고 이는 지구에 표시돼
[12:50 PM] acemarke: 시각적으로는 구글 어스 데스크탑의 레이아웃이랑 비슷해: http://elmcip.net/sites/default/files/platform_images/launch_google_earth.jpg
12:50 PM] acemarke: 지구를 놓고, 폼들과 탭드 섹션을 오른쪽 창 세 번째의 아래쪽 두는거지
[12:52 PM] acemarke: 나의 이 특정 앱에서는 꽤 무거운 중첩 구조를 갖고 있으면서도, 폼에 항목을 표시/편집 하고, 지구본을 렌더링하고, 그 선택이나 편집에 대한 모든 정보를 업데이트 해야해
[12:52 PM] acemarke: 내 최상위 몇몇 계층은 pure presentational and dumb 컴포넌트야
[12:52 PM] acemarke: TreeView도 최상위에 있고 마찬가지로 presentational이고 dumb지. 하지만 각 데이터 타입에 따라 “ConnectedFolder” 트리 아이템을 표시해
[12:53 PM] acemarke: 개별적으로 중첩된 트리 항목들은 “자신을 위한 데이터만 가져와서 자식들에게 ID만 전달한다” 는 패러다임을 따르지
[12:53 PM] acemarke: 그리고 트리의 하위 노드들은 expand된 경우에만 렌더하지
12:54 PM] acemarke: 꽤 심각한 중첩 구조지, 하지만 트리를 클릭해서 현재 선택한 항목을 변경한 경우 적절한 속성 폼과, 해당되는 개별 지구본 표시 컴포넌트만 실제로 업데이트돼
12:55 PM] acemarke: 컴포넌트 인스턴스 별로 메모이즈드 셀렉터를 사용하여 트리 항목에 대한 최적화를 할 필요는 아직 없지만, 성능이 이슈가 된다면 그렇게 해야겠지. 항상 나중에 할 수 있는 어떤 것이 있어
[12:56 PM] acemarke: 그래 이런 사고 과정과 구조가 내게 영향을 미친 거야
12:58 PM] acemarke: 또 MobX와 Redux 벤치마크에서 Dan Abramove의 최근 최적화도 말이지: https://twitter.com/dan_abramov/status/720219615041859584 , https://github.com/mweststrate/redux-todomvc/pulls?q=is%3Apr+is%3Aclosed
[12:59 PM] acemarke: 마지막으로 다양한 connected() 접근 방법으로 Redux를 최적화하는 훌륭한 프레젠테이션이 있지: http://somebody32.github.io/high-performance-redux/
[1:00 PM] acemarke: 자 이제 다 말했어: 개인적으로는 순수한 탑-다운 방법은 날 짜증나게 해. 하지만, 정신적으로 그게 너에게 더 잘 맞는다면, 그렇게 해
[1:11 PM] jrajav:: 난 이제 상황을 더 잘 이해하고 있는 것처럼 느껴지네. @acemarke 다시 한번 자세한 토론에 대해 감사해
[1:12 PM] acemarke: 확실히. 텍스트로 벽쌓기는 내 특기지! :)
[1:13 PM] jrajav:: 내 생각에 난 아직도 순수한 함수형 스타일로 앱을 작성해보고 싶은 것 같아. 아마도 성능에 대한 우려가 있을 수 있지만 이 애플리케이션은 성능에 그렇게 연관되지는 않아. 하지만 아마도 아주 큰 상태 트리를 갖게되면 트리의 각 레벨에서 하위 속성을 빼낼 수 있도록 효율적으로 조직하는 방법을 알고 싶어. 그리고 실제로 얼만큼 지저분해 질 수 있는지도 말이야
[1:14 PM] acemarke: 내가 절대 질문하지 않았다고 추측되네: 네 앱이 어떤 앱이며 어떤 종류의 데이터가 있는지?
[1:15 PM] jrajav:: 상대적으로 간단한 검색-표시 앱이야
[1:15 PM] jrajav:: 메인 페이지는 고급 기능이 포함된 검색 뷰가 있고, 사이드바에는 필터링, 자동완성, 페이지네이션, 용어 강조 같은 것들이 있지
[1:16 PM] jrajav:: 검색 결과는 각 항목에 대한 세부 보기로 링크되고, 대부분 수십 개의 정적인 세부 속성들이 여러 탭 및 뷰로 확산되지
[1:18 PM] jrajav:: 따라서 상태 트리는 쿼리를 위한 ‘search’ 객체, ‘searchResults’ 객체(‘검색’ 아래쪽에 중첩시킬 것을 고려중이야)가 될것이고, 그리고 선택한 아이템에 대한 ‘details’ 객체로 분리될 거야
[1:19 PM] jrajav:: 관리 및 성능에 관련한 큰 문제와 맞닥뜨리기에는 앱이 너무 간단하지만 적절한 조직화에 대한 이해와 최소한의 props 전달에 대해 이해하는 것은 충분히 복잡하네
[1:22 PM] acemarke: 잡았다. ThingEditor 예제와 완전히 다른 건 아니네
[1:22 PM] acemarke: 그리고 성능을 강조해야만 하는 것도 아닌 것 처럼 들리고