
Redux 성능 향상을 위한 컴포넌트 리팩토링
By Shahzad Aziz
프론트엔드 웹 개발은 빠르게 진화하고 있다. 매일 새로운 모범 사례에 도전하는 새로운 툴과 라이브러리가 발표된다. 신이 나기도 하지만, 역시 따라가기 벅차다. 개발자의 삶을 편안하게 해주는 새로운 도구 중 하나는 인기 오픈소스 상태 컨테이너인 Redux다. 지난 해 Yahoo! Search 팀은 Redux를 사용해서 데이터 분석에 사용되는 레거시 도구를 새로 고쳤다. Redux와 함께 사용하는 역시 매우 인기있는 프론트엔드 컴포넌트 라이브러리인 React를 사용하여 결합했다. Yahoo Search의 규모로 인해 매초마다 수천개의 측정 항목을 데이터 그리드에 저장한다. 우리의 데이터 분석 툴은 우리 Search 팀의 내부 유저가 저장된 데이터에 쿼리를 날려 트래픽과 A/B를 비교하는 테스트를 할 수 있도록 한다. 새로운 도구를 만드는 가장 큰 목적은 속도와 편의성이였다. 처음 시작했을 때부터 우리는 애플리케이션이 복잡해질 것이며 많은 상태를 보유하게 될 것이라는 걸 알았다. 개발과정에서 예상치 못한 성능 병목현상이 발생했다. 우리는 기술 스택에서 기대했던 성능을 달성하기 위해 깊이 파고들었고 리팩토링을 했다. 이 경험을 공유하고 Redux를 사용하는 개발자에게 React 컴포넌트와 상태 구조에 대한 추론을 통해 애플리케이션 성능을 높이고 쉽게 확장할 수 있도록 하려 한다.
Redux는 당신이 애플리케이션의 상태 변경을 예측 가능하게 하고 쉽게 디버그할 수 있기를 바란다. 이를 Flux 패턴의 아이디어를 애플리케이션의 상태를 단일 저장소에 저장하게 확장함으로써 달성한다. 리듀서를 사용하여 논리적으로 상태를 분할하고 책임을 괌리할 수 있게 한다. React 컴포넌트는 Redux 저장소의 변경 사항을 구독한다. 프론트엔드 개발자에게는 매우 매력적인 멋진 디버깅 도구를 상상할 수 있게 한다.
React를 사용하면 컨테이너와 프리젠테이셔널의 두 가지 카테고리로 컴포넌트를 추론하고 생성하는 것이 쉬워진다. 여기서 더 읽어볼 수 있다. 요점은 컨테이너 컴포넌트가 상태에 대해 구독하고 프리젠테이셔널이 전달된 프로퍼티를 이용해 마크업 렌더링을 한다는 것이다. Redux 문서 초반부에서 우리는 컴포넌트 트리 최상위에 컨테이너 컴포넌트를 추가해야 한다는 것을 알 수 있다. 우리 애플리케이션에서 가장 중요한 부분은 대화형 ResultsTable 컴포넌트다. 간결하게 하기 위해서 게시물의 나머지 부분에서는 이 컴포넌트에 집중할 것이다.
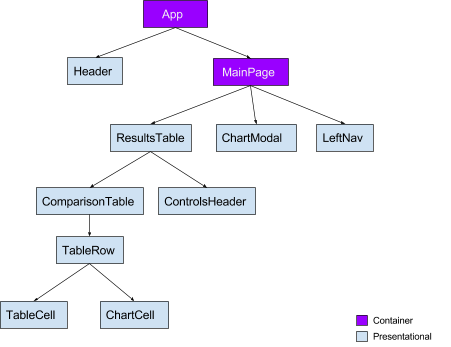
API에서 최적의 성능을 얻기 위해서 백엔드에 많은 수의 간단한 호출을 수행하고 리듀서에서 이 데이터를 결합하고 필터링한다. 이것은 많은 비동기 액션을 통해 데이터 조각을 가져오고 redux-thunk를 사용하여 제어 흐름을 관리한다는 것을 의미한다. 그러나 사용자의 선택이 변경되면 상태에서 가져온 대부분의 항목이 무효화되므로 다시 가져와야 한다. 대체적으로 꽤 잘 동작하지만, 응답이 돌아옴에 따라 상태도 여러번 변경된다는 의미다.
문제점
API에서 큰 성능 향상을 거두는 동안 브라우저의 프레임 그래프는 클라이언트의 성능 병목 현상을 나타내기 시작했다. 컴포넌트 트리의 상위에 있는 MainPage 컴포넌트는 모든 디스패치에 대해 다시 렌더링되었다. 컴포넌트는 렌더링에 비용 많이 드는 작업이 아니여야만 했지만 엄청난 양의 데이터 행이 있었다. 재 렌더링을 위한 델타 시간은 수초 이상 걸렸다.
어떻게 렌더링 성능을 향상시킬 수 있을까? 잘 알려진 메서드는 shouldComponentUpdate 메서드고, 여기서 시작해보았다. 이 방법은 컴포넌트 트리 전체에서 신중하게 구현해야 하는 일반적인 성능 향상 방법이다. 컴포넌트가 원하는 props가 변경되지 않은 경우에는 재 렌더링을 피할수 있도록 필터링할 수 있었다.
shouldComponentUpdate 개선에도 여전히 전체 UI가 갑갑했다. 사용자의 액션에 대한 응답은 지연되었고, 로딩 인디케이터는 한참 후에 나타났고, 목록 자동완성은 엄청 시간이 걸렸고, 아주 작은 사용자 상호작용조차 느리고 무거왔다. 요점은 React 렌더링 성능이 아니었다.
병목현상을 확인하기 위해 React Performance Tools 및 React Render Visualizer라는 두 가지 도구를 사용했다. 실험은 여러가지 다른 액션들을 수행한 뒤에 주요 컴포넌트에 대해 렌더 횟수 및 인스턴스 수에 대한 테이블을 만드는 것이었다.
아래는 우리가 만든 테이블 중 하나다. 빈번하게 사용되는 두 가지 액션을 분석했다. 앞서 말한 우리의 메인 테이블 컴포넌트에 대해 얼마나 많은 렌더가 트리거되는지 살펴보았다.
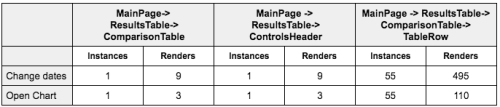
날짜 변경: 사용자는 기록된 데이터를 가져오기 위해 날짜를 변경할 수 있다. 데이터를 가져오려면 모든 메트릭에 대해 병렬적으로 API를 호출하고 Reducer에서 이를 병합했다.
차트 열기: 사용자는 측정 항목을 선택하여 일별로 꺾은선 차트에 표시할 수 있다. 이것은 모달 다이얼로그를 연다.
실험을 통해 상태가 트리를 통과하면서 관련 컴포넌트에 영향을 미치기 전에 반복적으로 많은 것들을 다시 계산해야 한다는 사실이 밝혀졌다. 이것은 비용이 많이 들고 CPU를 많이 사용했다. UI로 제품을 변경하면 React는 1080ms나 되는 시간을 테이블 및 행 컴포넌트에 사용했다. 우리 쓰레드를 바쁘게 만든 것이 공유된 상태의 문제라는 것을 깨닫는 것이 중요했다. React의 가상 DOM의 성능은 좋지만 가상 DOM을 생성하는 것을 최소화하기 위해 노력해야 한다. 이것은 렌더링을 최소화한다는 것을 의미한다.
성능 리팩토링
주된 생각은 컨테이너 컴포넌트를 살펴보고 상태를 보다 균등하게 컴포넌트 트리에 분산시키려고 시도하는 것이었다. 상태에 대해 더 생각해보고 덜 공유하고 덜 파생하게 만들고 싶었다. 가장 필수적인 아이템을 상태에 저장하고 컴포넌트에서 필요한 상태를 계산하고 싶었다.
리팩토링은 두 단계로 나누어 실행했다:
1단계. 컴포넌트 전반에 걸쳐 상태를 구독하는 컨테이너 컴포넌트를 더 추가했다. 배타적인 상태를 소비하는 컴포넌트는 상위에 컨테이너 컴포넌트가 필요하지 않다. 그 컴포넌트들은 배타적인 상태를 구독하는 컨테이너 컴포넌트가 될 수 있었다. 이것은 React가 Redux 액션에 대한 작업을 크게 줄여준다.
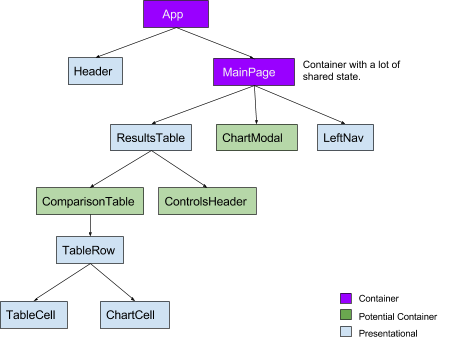
우리는 상태가 트리에서 어떻게 활용되고 있는지 식별했다. 가장 중요한 질문은 “배타적인 상태의 컨테이너 컴포넌트가 더 많이 있는지 확인하는 방법은 무엇인가?”였다. 이를 위해 몇 가지 주요 컴포넌트를 분할하여 컨테이너로 포장하거나 컨테이너 자체로 만들어야 했다.
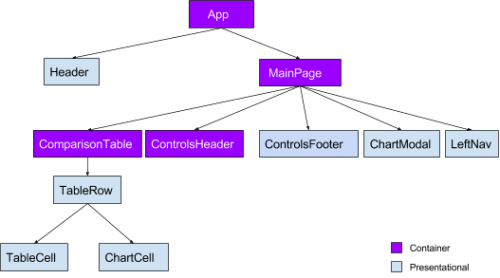
위의 트리에서 MainPage 컨테이너가 더 이상 임의의 테이블 렌더링을 담당하지 않는 것에 유의하라. ResultsTable에서 배타적인 상태를 가진 ControlsFooter를 추출했다. 우리가 집중한 것은 테이블 관련된 컴포넌트의 재 렌더링을 줄이는 것이었다.
2단계. 파생 상태와 shouldComponentUpdate
상태가 잘 정의되고 플랫한지 확인하는 것이 가장 중요하다. Redux 상태를 데이터베이스로 생각하고 정규화하기 시작하면 더 쉽다. 우리는 제품, 통계, 결과, 차트 데이터, 사용자 선택, UI 상테 등과 같은 엔티티를 많이 가지고 있다. 대부분 키/값의 쌍으로 분류하고 중첩을 방지한다. 각 컨테이너 컴포넌트는 상태를 쿼리하고 데이터를 비정규화한다. 예를 들어, 내비게이션 메뉴 컴포넌트는 제품 ID로 메트릭 목록을 필터링해서 전체 메트릭 상태에서 쉽게 제품 메트릭을 추출할 필요가 있었다.
전체 상태에서 반복적으로 파생되는 모든 프로세스는 최적화할 수 있다. Redux Reselect로 들어가보자. Reselect는 파생 상태를 계산하기 위한 셀렉터를 정의하게 해준다. Reselect를 이용해 정의된 셀렉터는 효율성을 위해 이전 상태를 메모할 수 있고, 계단식으로 연결될 수 있다. 따라서 아래 함수를 이용해 셀렉터를 정의할 수 있다. 그리고 메트릭과 productId에 어떠한 변경이 없는 한, 메모해둔 복사본을 반환할 것이다.
getMetrics(productId, metrics) {
metrics.find(m => m.productId === productId)
}
우리는 모든 비동기 액션이 해결되었는지 확인하고, 상태를 다시 렌더링하기 전에 필요한 모든 것을 상태에 유지하려고 했다. 그래서 컨테이너 컴포넌트의 shouldComponentUpdate 메서드의 동작을 정의하기 위해 셀렉터를 만들었다(예. 테이블은 측정 항목 및 결과가 모두 로드된 경우에만 렌더링 된다). shouldComponentUpdate에서 모든 것을 직접 할 수도 있지만, 셀렉터를 이용하면 다르게 생각할 수 있음을 느꼈다. 컨테이너는 상태를 예측할 수 있게 되고 렌더링 전에 그 상태에서 대기한다. 렌더링 해야하는 상태는 해당 상태의 서브셋일 수 있었다. 더 언급할 필요 없이 더 성능이 뛰어났다.
결과
리팩토링을 마친 후에 다시 실험을 해보아 모든 변경 사항의 영향을 비교했다. 컴포넌트 트리 전체에 걸친 상태 변화를 개선하고 더 향상되기를 기대했다.
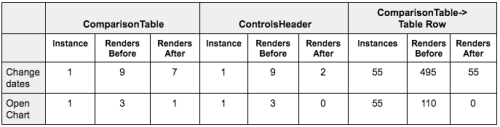
위의 표를 보면 한눈에 리팩토링이 어떤 영향을 끼쳤는지 명확히 알 수 있다. 새로운 결과에서는 날짜 변경이 어떻게 comparisonTable(7)과 controlsHeader(2) 간 렌더 횟수를 분배시키는지 관찰할 수 있다. 더해봤자 9번이다. 이러한 논리적인 리팩토링은 최대 4배까지 성능을 높일 수 있었다. 또한 React가 낭비하는 시간을 쉽게 최적화할 수 있었다. 이는 아주 중요한 개선사항이였으며 올바른 방향으로 나아가는 것이었다.
향후 계획
Redux는 프론트엔트 애플리케이션을 위한 훌륭한 패턴이다. 애플리케이션 상태를 더 잘 판단할 수 있게 해주었고, 하나의 스토어를 사용하는 것이 앱이 복잡해짐에 따라 확장하는 것이나 디버깅하는 것을 쉽게 했다.
앞으로는 Redux State를 위한 immutability를 알아보려고 한다. Redux의 상태 변경에 대해 규칙을 정하고 shouldComponentUpdate에서 shallow comparison를 이용하는 경우를 생각하려고 한다.